| |
|
|
| ▶ |
개요 |
|
| |
|
|
| |
UDS(User data source)는 AI Report가 제공하는 '사용자 정의 데이터에 대한 범용 인터페이스'로서, DB접속의 산업 표준이라 할 수 있는 JDBC/ODBC로 처리할 수 없는(또는 적합하지 않은) 데이터 소스에 대한 표준적인 접근 및 제어 방법을 제공합니다.
즉, AI Report의 개발자는 JDBC/ODBC를 통해 RDBMS를 사용하는 것과 동일한 수준으로 UDS를 통해 사용자 데이터를 보고서에 통합할 수 있습니다. |
|
| |
|
|
| ▶ |
UDS의 구분 |
|
| |
|
|
| |
UDS는 사용방법, 즉 개발자의 구현방법에 따라 크게 CSV/XML Set과 User Set으로 구분합니다.
CSV/XML Set은 개발자가 별도의 코딩을 하지 않고, 데이터 소스를 분석하기 위한 메타 정보만 리포트 개발 시 AI디자이너에서 기술하여 주는 유형입니다.
User Set은 메타 정보의 기술과 함께, AI Report가 제공하는 Java 추상 클래스를 개발자가 상속 받아 구현하는 유형이며,
사용자 구현 클래스에서 생성하는 데이터 Set의 형태에 따라 다시 '스트링 배열(2차원), Vector, CSV, XML'로 구분되며 개발자는 이 중 하나를 선택하여 구현하면 됩니다.
|
|
| |
|
|
| ▶ |
UDS의 자료형 |
|
| |
|
|
| |
AI Report는 CGI 언어의 자료형과 DB 자료형의 매핑을 위해 내부적으로 문자형, 정수형, 실수형으로 범주화된 단순 자료형(데이터 타입)을 사용하고 있으며,
이 규칙은 UDS에서도 동일하게 적용됩니다.
UDS에서는 사용자 데이터의 분석정보를 메타 정보라는 항목으로 직접 기술해 주어야 하며 이 때 자료형은 다음 식별자 중 하나를 사용해야 합니다.
| 식별자 |
자료형 |
| 문자형 |
STR |
| 정수형 |
INT |
| 실수형 |
FLOAT |
|
|
| |
|
|
| ▶ |
UDS 사용을 위한 환경설정 |
|
| |
|
|
| |
UDS는 Java 환경에서 구현되므로, UDS를 사용한 보고서가 배치되는 웹 컨테이너(WAS)의 CLASSPATH상에 아래의 모듈들이 추가되어야 합니다.
- UDS 라이브러리 : 제품과 함께 배포되는 모든 JAR 파일(ai.uds.jar 등) <- 배포 CD 내 'UDS >lib' 폴더 확인
- 사용자 직접 구현 클래스 및 관련 라이브러리 : User Set인 경우
|
|
| |
|
|
| ▶ |
CSV / XML Set |
|
| |
|
|
| |
CSV/XML Set은 사용자 데이터가 CSV나 XML의 형식으로 존재하고(파일 또는 동적 생성), 일정한 파일 형식이 있어 정형화 된 Data Set으로 가공이 가능한 경우에 적용 가능한 방법이며, Local 데이터 소스를 처리하는 File과 웹 리소스를 처리하는 HTTP로 구분됩니다.
File은 개발된 리포트가 구동되는 웹 서버 상에 존재하는 정적 파일을 처리하는데 사용하고, HTTP는 데이터가 웹 애플리케이션에 의해 동적으로 생성되는 경우에 사용합니다. HTTP의 경우 웹 애플리케이션의 실행 옵션을 위해 CGI 파라미터를 사용할 수 있습니다.
1. CSV(Comma separated values) Set
1-1. 지원되는 CSV 파일 형식
- 개행 된 라인 별로 하나의 레코드(데이터 필드의 집합)가 존재
- 파일 전체에 걸쳐 단일 필드 구분자(TAB)를 사용
- 모든 레코드는 동일한 수의 필드를 가짐
1-2. 사용방법
① AI Designer 화면 왼쪽 Database 정보 창의 UDS > CSV Set 항목을 마우스의 우측버튼으로 클릭한 후 CSV 데이터 소스 추가를 선택합니다.
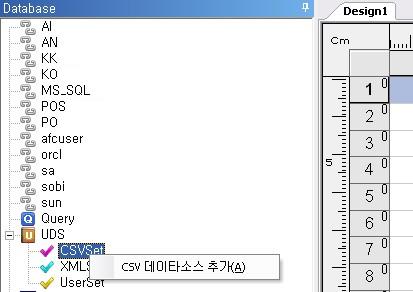
② 설정 창에서 아래의 정보를 입력합니다.

| 항목 |
내용 |
| 데이터 소스 명 |
해당 데이터 소스를 시스템적으로 구분하는 식별자
(사용자는 확장성을 고려하여 영/숫자만 사용해야 함 ) |
| 데이터 소스 유형 |
File 또는 HTTP |
| URL(PATH) |
- File인 경우 리포트가 실행(배치)되는 웹 서버 상에서 유효한 파일의 절대경로
예) /usr/local/data/user-define.csv (UNIX인 경우)
D:\data\user-define.csv (Windows인 경우)
- HTTP인 경우 런 타임 시 호출할 CGI (웹 애플리케이션)의 절대 URL
예) http://myhost/uds/csv-gen.jsp |
| 디자인 시 사용할 파일 |
File인 경우 디자인 시 미리 보기에 사용되는 local상의 임시파일로 서버 상의 실제 파일과 형식이 동일해야 합니다.(필수) |
HTTP 파라미터
(HTTP 인 경우 ) |
위에서 지정한 URL에 전달될 CGI 파라미터 (query string)를 의미하며 name1=value1&name2=value2의 형식으로 기술해 줍니다. (옵션)
name과 value 부분에는 디자인 시 정의한 파라미터를 ^param_name^의 형식으로 사용할 수 있으며, 이 경우 실행 시에 리포트의 CGI 파라미터 값으로 대체되어 URL에 전달됩니다.
예) category=csv&area_code=^param_code^
param_code 파라미터의 값이 11인 경우 category=csv&area_code=11의 query string이 URL상의 CGI로 전달됩니다.
|
HTTP Method
(HTTP인 경우) |
위의 지정한 URL의 CGI가 파라미터를 처리하는 HTTP method (GET/POST) |
| 구분자 |
레코드를 구성하는 필드를 구분하는 문자열 (TAB). 콤마는 사용 불가 |
| 인코딩 |
CSV파일의 character encoding을 지정합니다.
ISO/8859는 컴퓨터에서 8비트로 문자를 나타내기 위한 ISO와 IEC의 공동 표준이며, KSC5601은 한글 완성형 표준(한글 2,350자 표현)규격으로 한글 코드를 유니 코드로 변환해줍니다. |
| 처리시작 라인 |
CSV파일에서 데이터 레코드로 처리되어야 하는 첫 라인 번호를 지정합니다.
파일의 처음부분에 필드 정보나 공백 라인 등이 있는 경우 이 내용이 데이터로 처리되면 안 되므로 반드시 지정해야 합니다. |
| 메타정보 |
URL(PATH)항목에 지정된 파일(또는 Stream)을 파싱하여 레코드의 집합인 데이터 Set으로 변환하기 위해 기술해 주는 파일형식 정보를 말하며, AI Report의 UDS 처리모듈(라이브러리)은 사용자가 기술한 이 메타정보를 토대로 필드, 레코드, 데이터 Set 등의 처리 단위로 데이터를 변환합니다.
※ 기술형식 : <필드명1[:TYPE]>...<필드명2[:TYPE]>
- 필드명 : 레코드를 구성하는 개별 필드의 이름
- TYPE : 해당 필드의 자료형(STR | INT | FLOAT)을 필요 시 기술하며 기술하지 않는 경우 기본값은 STR(String)입니다.
예) <no><name><age:INT> |
③ 모든 설정정보를 입력한 후 확인버튼을 클릭하면 DB정보창의 UDS >CSV Set 하위에 위에서 지정한 데이터 소스 명으로 데이터 소스가 추가 됩니다.
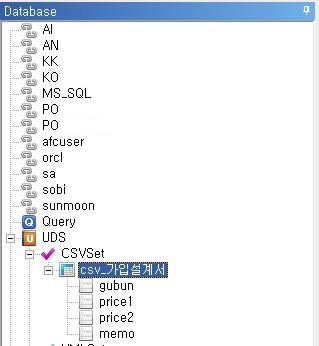
④ 이후의 사용법은 쿼리 변수와 동일합니다.
1-3. 참고
- 모든 필드의 정보를 기술해야 합니다.
- 필드정보는 파일에서의 물리적인 데이터 순서와 동일하게 순차적으로 기술되어야 합니다.
- 메타정보를 만족하지 않는 행의 자료는 무효화 됩니다.(보고서 조회 불가)
2. XML Set
2-1. 지원되는 XML 파일 형식
Well-formed document
XML 문서에 쓰인 요소들이 모두 시작 태그와 끝 태그를 가지고 있고, 중첩 규칙을 위반하지 않는 문서, DTD가 없는 XML 문서를 비 검증용 파서(non-validating parser)로 파싱 했을 때 오류가 없는 문서, XML 문서를 Internet Explorer 5로 읽었을 때 오류가 없는 문서를 의미한다.
- 데이터 Set 노드와 레코드 노드를 포함해야 합니다.(아래 설명 참조)
- 필드 값은 다음 4가지 경우 중 하나 이어야 합니다.
① Element의 값 사용 : <element_name>
② Element의 Attribute 사용 : <element@attrName>
③ 레코드 노드의 Attribute 자체를 필드로 사용 : <@attrName>
④ 레코드 노드의 값 자체를 필드로 사용 : <#TEXT>
예) <!@id:INT><name/first><name/last><age:INT><!area@code:INT>
2-2. 지원되는 XML 파일 예제
<유형 1>
<?xml version="1.0"?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications with XML.</description>
</book>
....(중략)....
<book id="bk102">
<author>Ralls, Kim</author>
<title>Midnight Rain</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-12-16</publish_date>
<description>A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world.</description>
</book>
</category> |
<유형 2>
<?xml version="1.0" encoding="EUC-KR"?>
<Message>
<Body>
<M m1="Report01" m2="2">
<GP gp1="004030" gp2=" " gp3="테스트" gp4="7" gp5="2008.04"/>
<RCT rct1="12-34-5-6789 123 " rct2="a" rct3="2008"/>
<SFF sff1="19800229" sff2="홍길동" sff8="hong@knisoft.com" sff9=""/>
</M>
</Body>
</Message> |
<유형 3 >
<?xml version="1.0"?>
<!DOCTYPE book SYSTEM "http://www.ai-report.com/UDS/xml/book.dtd">
<book>
<title>Data on the Web</title>
<author>Serge Abiteboul</author>
<section id="intro" difficulty="easy" >
<title>Introduction</title>
<p>Text ... </p>
<section>
<title>Audience</title>
<p>Text ... </p>
</section>
<section>
<title>Web Data and the Two Cultures</title>
<p>Text ... </p>
<figure height="400" width="400">
<title>Traditional client/server architecture</title>
<image source="csarch.gif"/>
</figure>
</section>
</section>
</book>
|
2-3. 사용방법
① AI Designer 화면 왼쪽 Database 정보 창의 UDS > XML Set 항목을 마우스의 우측버튼으로 클릭한 후 XML 데이터 소스 추가를 선택합니다.
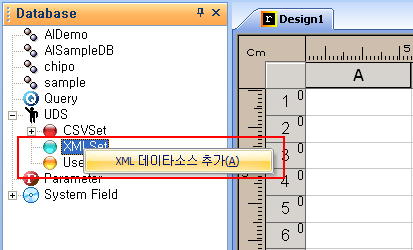
② 설정 창에서 아래의 정보를 입력합니다.
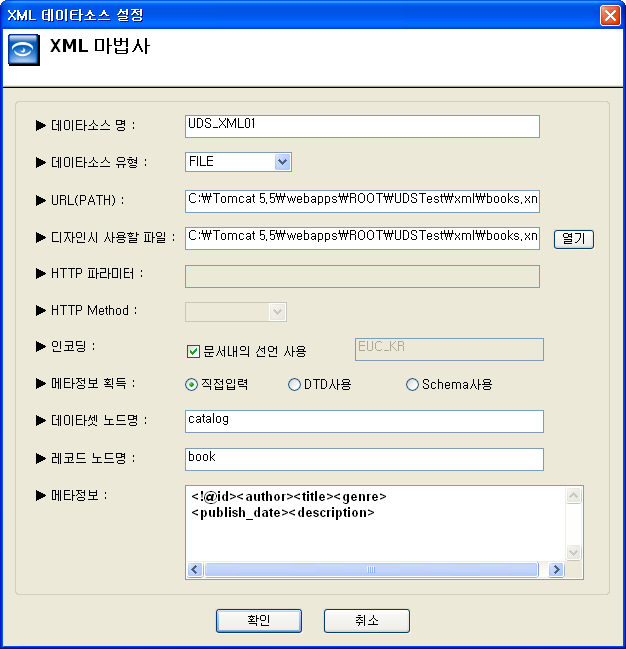
| 항목 |
내용 |
| 데이터 소스 명 |
해당 데이터 소스를 시스템적으로 구분하는 식별자
(사용자는 확장성을 고려하여 영/숫자만 사용해야 함 ) |
| 데이터 소스 유형 |
File 또는 HTTP |
| URL(PATH) |
- File인 경우 리포트가 실행(배치)되는 웹 서버 상에서 유효한 파일의 절대경로
예) /usr/local/data/user-define.xml (UNIX인 경우)
D:\data\user-define.xml (Windows인 경우)
- HTTP인 경우 런 타임 시 호출할 CGI (웹 애플리케이션)의 절대 URL
예) http://myhost/uds/xml-gen.jsp |
| 디자인 시 사용할 파일 |
File인 경우 디자인 시 미리 보기에 사용되는 local상의 임시파일로 서버 상의 실제 파일과 형식이 동일해야 함.(필수) |
HTTP 파라미터
(HTTP 인 경우 ) |
위에서 지정한 URL에 전달될 CGI 파라미터 (query string)를 의미하며 name1=value1&name2=value2의 형식으로 기술. (옵션)
name과 value 부분에는 디자인 시 정의한 파라미터를 ^param_name^의 형식으로 사용할 수 있으며, 이 경우 실행 시에 리포트의 CGI 파라미터 값으로 대체되어 URL에 전달.
예) category=csv&area_code=^param_code^
param_code 파라미터의 값이 11인 경우 category=csv&area_code=11의 query string이 URL상의 CGI로 전달. |
HTTP Method
(HTTP인 경우) |
위의 지정한 URL의 CGI가 파라미터를 처리하는 HTTP method (GET/POST) |
| 인코딩 |
|
| 구분자 |
레코드를 구성하는 필드를 구분하는 문자열 (TAB). 콤마는 사용 불가 |
| 인코딩 |
XML 문서를 처리할 때 문서 내에 선언되어있는 인코딩 값을 사용하거나 지정한 인코딩 값(EUC-KR)을 사용할 수 있음. (Default : 문서 내 선언 값)
※ EUC-KR : 영문자 이외의 문자를 지원하기 위해 제안한 확장 유닉스 코드(Extend UNIX Code)중 한글 인코딩 방식으로, XML에서 한글을 사용한다면 인코딩을 아래와 같이 "EUC-KR" 인코딩을 사용해야 합니다.
XML파일 내 인코딩이 EUC-KR로 되어있지 않은 경우 디자이너에서 선택하여 인코딩을 할 수 있습니다. |
| 메타정보 획득 |
하단 메타정보 획득 유형을 선택.
- 직접입력 : 데이터 셋 노드명 , 레코드 노드명 , 메타정보 등을 사용자가 직접 입력
- DTD 사용 : DTD(Document Type Definition) 문서를 포함하고 있는 xml 정보를 읽을 때 활용. DTD 마법사를 통해 값을 획득하여 메타정보에 자동으로 매핑시킴.
- Schema 사용 : Schema 마법사를 통해 값을 획득하여 메타정보에 자동으로 매핑시킴. |
| 데이터 셋 노드명 |
xml 파일에서 데이터 처리 시작과 끝의 지시자로 사용할 Element명을 의미.
하단의 레코드 노드명을 모두 포함하는 적격한 Element를 지정.
- 기본값 : @All -> 데이터 셋 노드의 제약이 없음 |
| 레코드 노드명 |
xml 파일에서 필드들의 집합인 레코드를 구성하는 Element명을 의미.
하단의 메타정보는 이 레코드 노드의 하위 Element 중 데이터 필드로 사용될 Element에 대하여 기술.
|
| 메타정보 |
URL(PATH)항목에 지정된 파일(또는 Stream)을 파싱하여 레코드의 집합인 데이터 Set으로 변환하기 위해 기술해 주는 파일형식 정보를 말하며, AI Report의 UDS 처리모듈(라이브러리)은 사용자가 기술한 이 메타정보를 토대로 필드, 레코드, 데이터 Set 등의 처리 단위로 데이터를 변환합니다.
※ 기술형식 : <[!]노드명1[/sub-node][:TYPE]>...<노드명n[/sub-node][:TYPE]>
- ! : 해당 필드가 옵션인 경우, 노드명 앞에 기술. 필수 필드의 경우 필드가 존재하지 않는다면 해당 레코드는 무효화 처리됨.
- 노드명 : 필드 값으로 사용할 값을 가진 Element명을 지정.
- sub-node : 노드 Element가 하위 Element를 가지고 이 하위 Element를 필드로 사용할 경우. 그 계층(depth)을 '/'로 연결하여 기술.
- TYPE : 해당 필드의 자료형(STR | INT | FLOAT)을 필요 시 기술하며 기술하지 않는 경우 기본값은 STR(String)입니다.
예) <title><section/title><!section/figure:STR><price:FLOAT>
-> title과 section 하위의 title, price는 필수 필드이고, section 하위의 figure는 옵션 필드입니다. |
③ 모든 설정정보를 입력한 후 확인버튼을 클릭하면 DB정보창의 UDS >XML Set 하위에 위에서 지정한 데이터 소스명으로 데이터 소스가 추가 됩니다.
④ 이후의 사용법은 쿼리 변수와 동일합니다.
2-5. DTD 활용
DTD(Document Type Definition)란 XML문서 안의 데이터들에 대한 구조를 표현하는 규칙들의 집합입니다.
DTD는 XML 문서가 어떻게 구조화되고 어떤 요소를 포함해야 하며 어떤 종류의 데이터로 구성 되어야 하는지 등을 규정하는 규칙을 정의하고 있습니다.
DTD는 XML Document안에 내포된(Internal) 형태의 DTD와 별도의 파일로 존재하는 외포된(External) 형태의 DTD로 구분됩니다.
AIReport는 두 종류의 DTD를 모두 지원하며, DTD에 연결된 XML문서는 유효한(Valid) 문서이어야 합니다.
2-5-1. dtd 사용 xml 파일 예제(book.xml)
| XML |
DTD |
<?xml version="1.0"?>
<!DOCTYPE book SYSTEM "http://localhost:8080/UDSTest/xml/book.dtd">
<book>
<title>Data on the Web</title>
<author>Serge Abiteboul</author>
<section id="syntax" difficulty="medium" >
<title>A Syntax For Data</title>
<p>Text ... </p>
<figure height="200" width="500">
<title>Graph representations of structures</title>
<image source="graphs.gif"/>
</figure>
<section>
<title>Base Types</title>
<p>Text ... </p>
</section>
</section>
</book> |
<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT book (title, author, section+)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT section (title, (p | figure | section)* )>
<!ATTLIST section
id ID #IMPLIED
difficulty CDATA #IMPLIED>
<!ELEMENT p (#PCDATA)>
<!ELEMENT figure (title, image)>
<!ATTLIST figure
width CDATA #REQUIRED
height CDATA #REQUIRED >
<!ELEMENT image EMPTY>
<!ATTLIST image
source CDATA #REQUIRED > |
2-5-2. DTD 마법사
DTD 마법사는 내포 또는 외포된 DTD를 파싱하여 구조화된 트리 형태로 표현합니다. 사용자는 리포트에 쓰일 데이터 셋 노드, 레코드 노드, 그리고 메타정보에 매핑 될 노드들을 Drag & Drop하여 직관적이고 쉽게 해당 정보를 설정할 수 있습니다.
<위 2-5-1의 book.xml DTD 마법사 실행 화면>
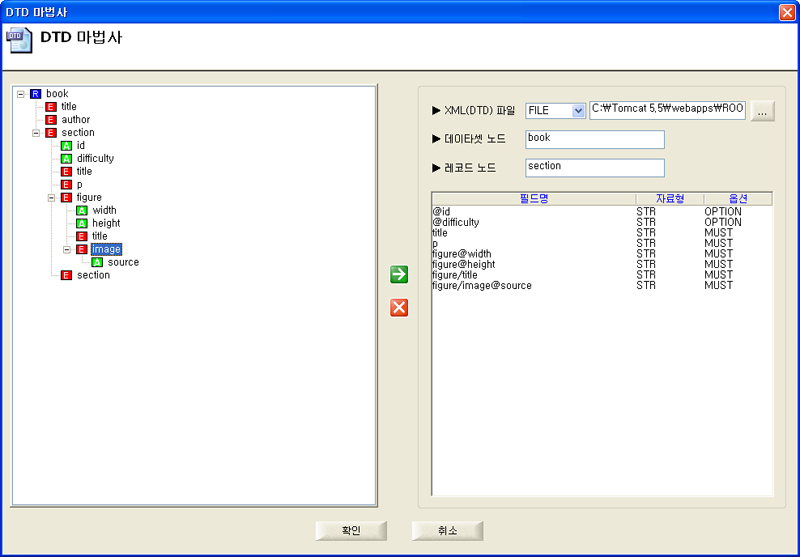
<DTD 마법사를 이용하여 레코드 노드 설정 후의 메타정보 결과>
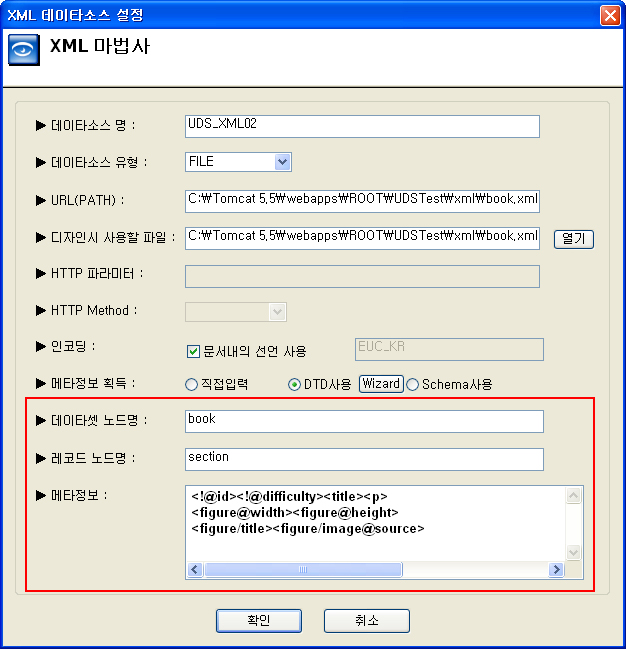
2-7. 참고
- 데이터 필드로 사용할 필드(Element)의 정보만 기술해 주면 됩니다.
- 필드정보는 파일에서의 물리적인 Element 순서와 동일할 필요는 없으나 순차적으로 기술하는 것이 바람직합니다.
- 메타정보를 만족하지 않는 행의 자료는 무효화 됩니다.(보고서 조회 불가)
|
|
|